
Earth observation filtering
Identify useful frames before downlinking full sensor captures.
belto lets satellite operators run AI models onboard constrained orbital hardware, turning raw sensor data into compact mission-ready insights before downlink.
Satellites operate under hard constraints: limited bandwidth, intermittent downlink, power budgets, memory limits, and mission-critical timing.
Earth observation, telemetry, and onboard sensors can produce more raw data than operators can downlink quickly.
Connectivity windows are constrained, intermittent, and expensive to use for raw data that may not be mission-relevant.
Cloud-first workflows force teams to wait until data reaches the ground before extracting operational insight.
belto packages models, rules, and mission constraints into deployable jobs that can run on constrained edge systems.
Run AI workflows close to the sensor, before raw data leaves the spacecraft or remote system.
Transmit structured alerts, detections, summaries, and prioritized outputs instead of unnecessary raw data.
Define jobs around mission constraints for bandwidth, latency, power, memory, and operating context.
Package model artifacts with rules, thresholds, and mission constraints.
Run inference and logic against sensor or telemetry streams near the source.
Reduce raw signals into compact, structured mission outputs.
Prioritize detections, alerts, and summaries for downlink.
belto is designed for workflows where insight is more valuable than raw volume.
Identify useful frames before downlinking full sensor captures.

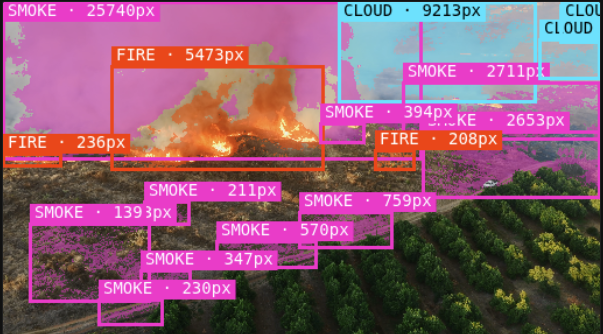
Flag likely wildfire signatures for faster operational awareness.

Prioritize maritime detections and regions of interest.

Surface unusual signals from onboard telemetry streams.

Detect patterns that may indicate operational risk.

Choose what should be transmitted first during narrow windows.
Keep AI workflows useful when links are limited or intermittent.
belto packages models, rules, and mission constraints into deployment jobs optimized for bandwidth, latency, power, and memory.
Bundle AI models, preprocessing rules, thresholds, metadata, and mission limits into a single deployable package.
Test expected behavior against constrained compute, memory, latency, and bandwidth assumptions before deployment.
Inspect what ran, what was detected, what was compressed, and what would be transmitted.
Login to the belto demo to deploy an AI package to a simulated satellite and inspect mission logs.
Read the belto research record for additional context on the technical direction behind the platform.
belto is built for teams exploring onboard intelligence, constrained inference, and mission-ready edge AI workflows.